
Projects

Anglo-American: Building the simulation system for Anglo-American's Proof-of-Concept zero haulage emissions hydrogen truck.
The team worked together to create simulations to enable strategic decision-making and planning for Anglo-American's industry-leading shift from diesel to hydrogen mining trucks - see a video overview of the project here. The work consisted of:
- Core modelling & simulation
- Stakeholder engagement
- Establishing metrics for system performance
- Data preparation and data pipeline development
- Productionizing the system for users & traceability
- Management of vendors to enhance the functionality of the modelling and user experience
- Cost modelling
The purpose of the simulation is to evaluate the performance characteristics of various configurations of a zero-emissions mine haulage system. The team implemented a Discrete Event Simulation of hydrogen production, transport and usage in an open pit mine. This simulation represents the key dynamics that determine the system performance including energy availability, physics of hydrogen production and queueing at hydrogen refuelling stations.
The Single Synthetic Environment Technology Demonstrator with UK Strategic Command and the British Army (Team Prior Experience Working at Improbable)

This project was a collaborative effort by industry, government and academia to bring together multiple models and data streams into a single platform in order to assist military planning. It involved complex modelling of civilian patterns of life, critical national infrastructure, weather, terrain and interaction with military entities.
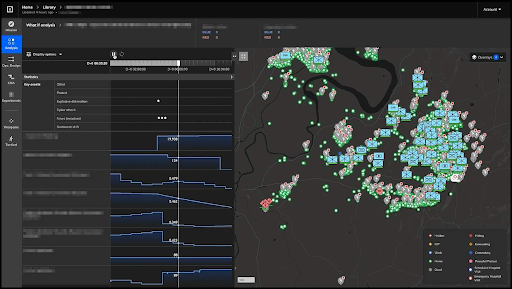
Work with the British Army involved building on the Single Synthetic Environment, integrating with multiple established industry partners and navigating various hurdles around data, equipment usage and facility access to bring together a technology demonstrator for next generation British Army training.
The most interesting element of this project was the blending of data between live and simulated components. Actions from real-world actors had knock-on consequences in the virtual world, and within that virtual world, more human players could take part. This demonstrated a path to greater realism, scale and complexity in training.
London Underground modelling and simulation: lead development of in-house simulations of complex sections of the railway and modelling of maintenance depots. (Team Prior Experience Working at TFL)

Between 2014 and 2018 Harry built a probabilistic modelling capability within the Systems Performance Engineering team at the London Underground. He developed a number of new Python-based discrete-event simulation models which are used for the modelling of complex sites across the London Underground network.
This new capability was used to solve engineering problems related to capacity and RAM (reliability, availability and maintainability) assessment for new capital programmes.
The depot modelling tool Harry developed was represented at the 2017 UK Rail in Industry Awards. It has been used to model maintenance performance of depots on the London Underground network in order to assess serviceability for future fleets.
Leading the Babylon Health Healthcheck Digital Twin Team & Re-architecting the Central Health Record Team (Team Prior experience working at Babylon)

Chris was a software engineer, tech lead and engineering manager at Healthtech unicorn Babylon Health for 3 years. During this time he led the engineering team of the flagship Healthcheck product from prototype to launch and ultimately scaling to over a million users in a dozen countries. Healthcheck includes a digital twin of the user's body:
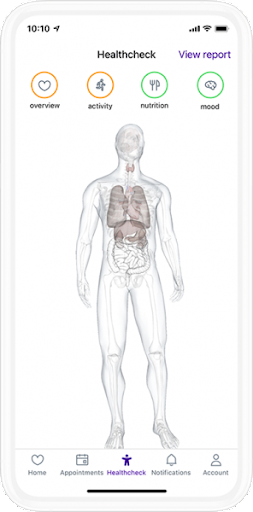
The creation of this product involved multi-disciplinary teams with backgrounds in science, medicine, software engineering, data engineering, and product management. Chris led the creation of dozens of web and mobile applications to deliver the necessary functionality at scale.
In his last year at Babylon, Chris led the re-architecting of the central health record platform. This was to enable collection of interoperable data from across the company, and from external partners such as hospitals and insurance companies. This required management of very large datasets (petabyte scale). Chris led the implementation of a Kafka-streams based data pipeline, with an elasticsearch-based querying functionality.
Complex health data had to be codified via standards (such a FHIR and SNOMED), and work with Babylon's existing Knowledge Graph system. However, the data collection pipeline needed to avoid burdening teams with undue complexity. This challenge was addressed via data tooling to reduce the FHIR schema complexity for teams, with a "rehydration" pipeline process prior to storage and querying. The knowledge graph system was also integrated in the pipeline, with the graph database information queried to enrich data prior to storage. This data was then made available via a GraphQL API (built on top of elasticsearch) for ease of exploration, and used to provide key insights to a variety of products, including the Healthcheck digital twin.
The rebuilding of the system took 9 months and was delivered on time. The monolithic single-point of failure that it replaced was decommissioned shortly after. A number of key database concepts and architectures had to be considered and trade-offs carefully evaluated in order for the project to succeed, notably consistency guarantees (particularly for read-after write compatibility), understanding the CAP theorem (and its limitations), performance under load, evolving data schemas over time, replication, encoding, cold-storage and retrieval, stream processing and fault tolerance in a distributed systems context